百度 抓 取
2021年5月27日—首先百度的抓取器会和网站的首页进行交互,拿到网站首页之后会对页面进行理解,理解包含(类型、价值计算),其次会把网站首页的所有超链接提取出来。,但目前我没有找到一个可以精准提取搜索引擎搜索结果的开源爬虫。于是,我便编写了这个爬取百度搜索...
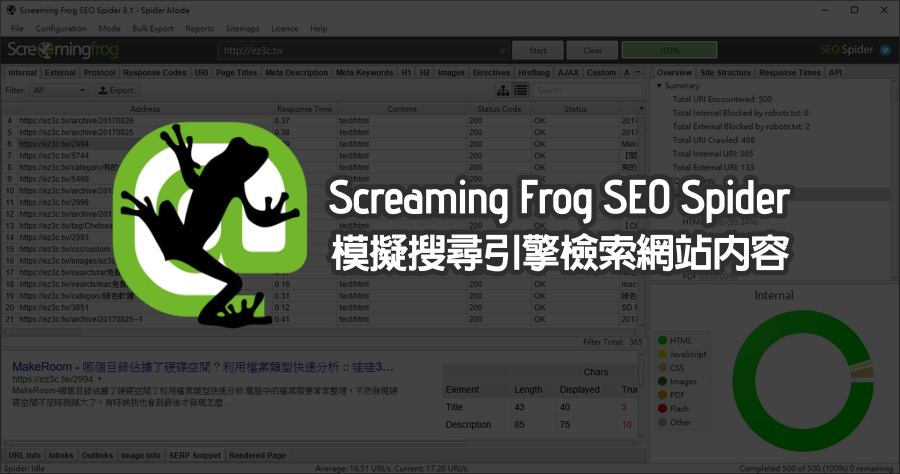
百度抓取器爬虫工作原理,网站抓取建设指南!
- 搜尋引擎排名
- google排序原則
- Meta name=robots
- 百度 抓 取
- web crawler
- 禁止 搜尋
- 搜尋引擎的爬蟲
- 谷歌蜘蛛
- Robot 禁止
- google搜尋引擎
- 網路蜘蛛
- <meta name= googlebot
- 蜘蛛爬行
- 網頁爬蟲工具
- 搜尋引擎原理
- 谷歌 爬虫工具
- 搜尋引擎設定
- 谷歌蜘蛛
- Robot .txt 是 什麼
- Robox txt
- 蜘蛛 查詢 器
- 最強搜尋引擎
- Robots deny all
- google搜尋引擎下載
- HTML 搜尋引擎
2021年5月27日—首先百度的抓取器会和网站的首页进行交互,拿到网站首页之后会对页面进行理解,理解包含(类型、价值计算),其次会把网站首页的所有超链接提取出来。
** 本站引用參考文章部分資訊,基於少量部分引用原則,為了避免造成過多外部連結,保留參考來源資訊而不直接連結,也請見諒 **
